Flows¶
A Flow defines how an experiment is executed, including device fabrication, data collection, and data analysis. Flows are a core concept in Balthazar and are required to run, track, and reproduce experiments.
Why Flows matter¶
Flows ensure that experiments are:
- Reproducible: the same steps can be run again at any time
- Versioned: changes to experimental logic are tracked
- Reviewable: experiment execution can be inspected and audited
All experiment execution in Balthazar happens through Flows.
What is a Flow?¶
A Flow is a standard Python script executed by the machine where the Balthazar Runner is installed. During execution, Balthazar automatically captures logs, outputs, and metadata associated with the run.
Creating and running a Flow¶
Follow the steps below to create and run your first Flow.
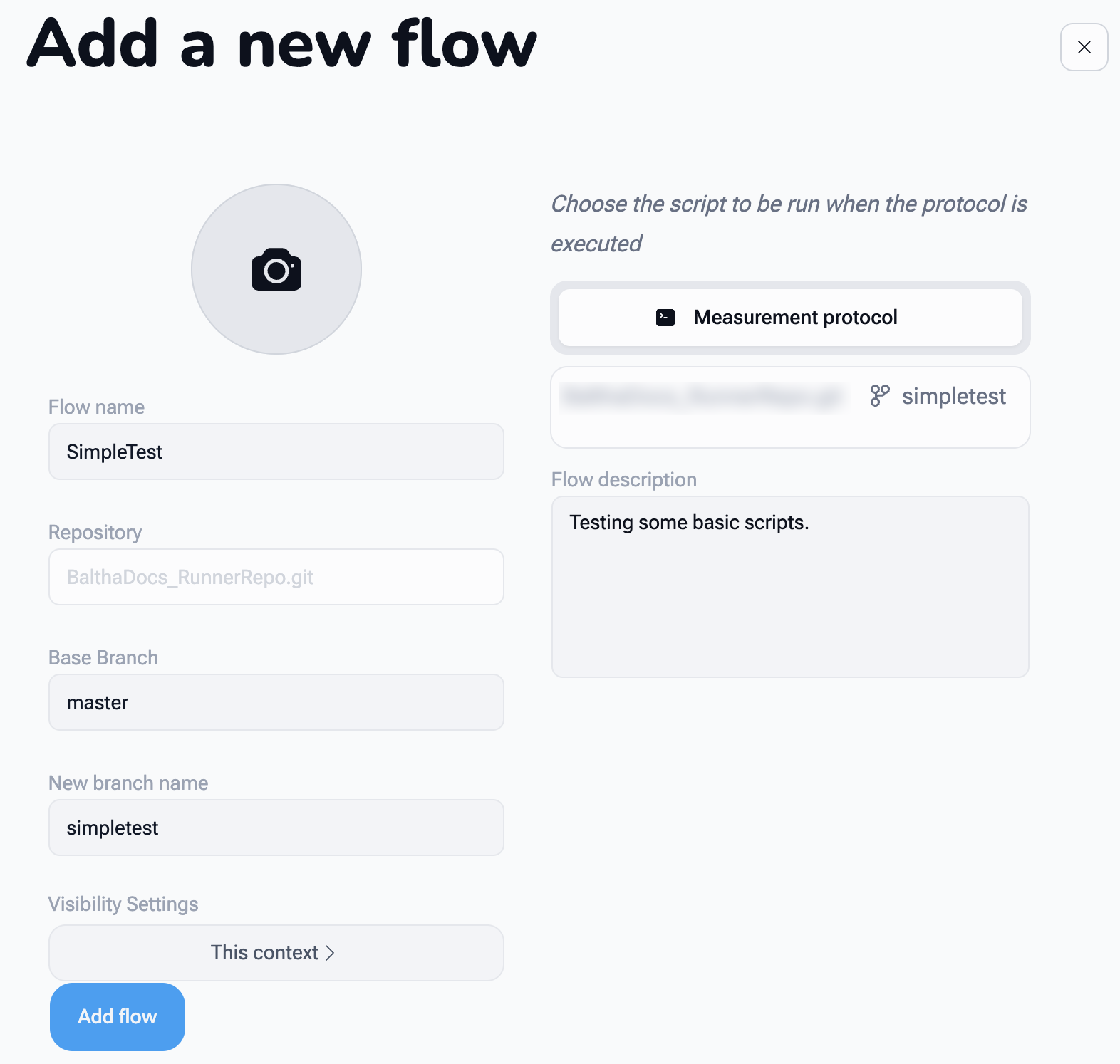
1. Create a new Flow¶
- Choose a Flow name (for example,
SimpleTest) - Click Add Flow
2. Open the workbench¶
The Workbench is the environment where Flows are developed, edited, and executed. It allows you to create Python scripts, run them interactively, and see outputs live.
- Click the Workbench button to start editing the Python scripts associated with your Flow
- Create a new file, for example
main.py. This file contains the main logic of your Flow
You can now write Python code as usual, including imports, computations, and plotting. When run through a Flow, Balthazar automatically captures outputs and plots for review both during and after the run.
3. Write a simple script¶
Add some code to main.py, for example:
a = 2
b = 3
c = a + b
print(c) # This will show 5 in the output
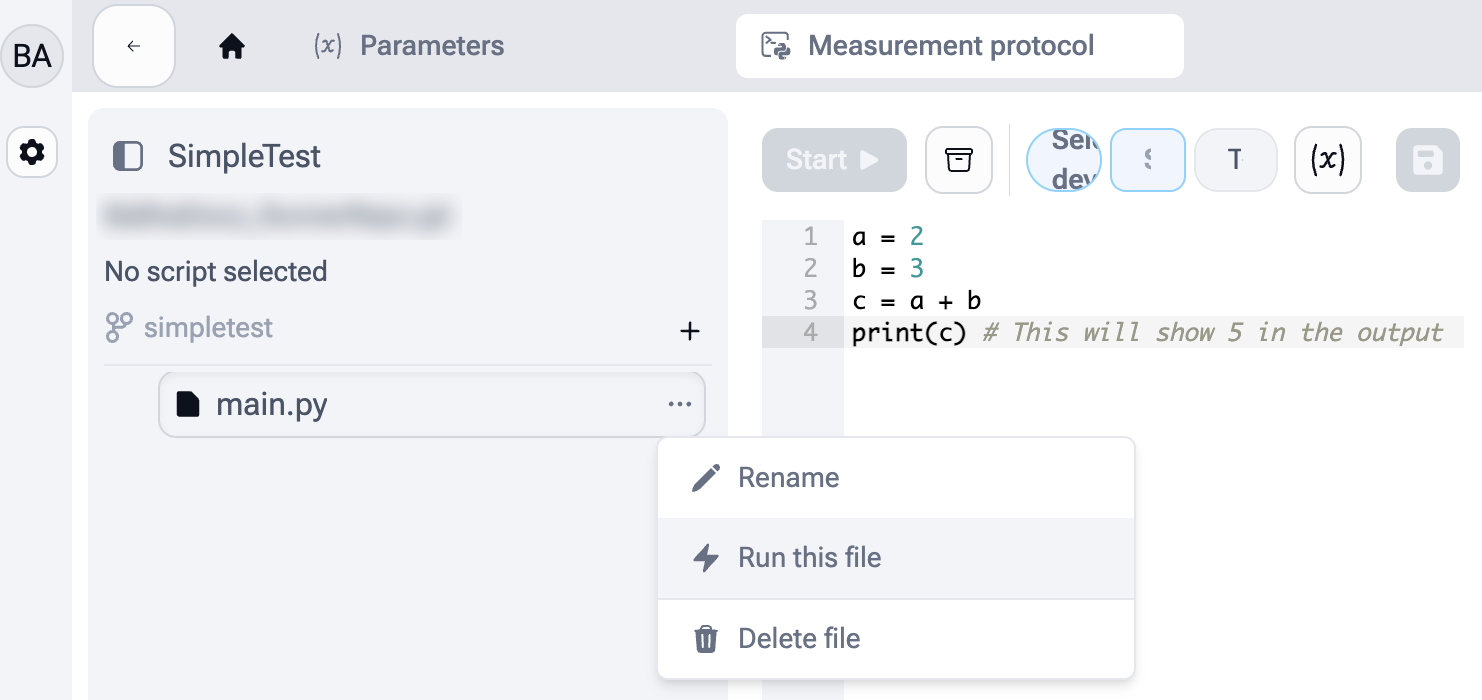
4. Run the script¶
- Click the three dots next to the filename
- Select Run this file to choose the main file of the Flow
5. Select a device and Runner¶
At this point, the Flow is ready to run:
-
Select a device
(see Creating a Device if your device list is empty) -
Select a Runner
(see Installing a Runner if no Runner is available)
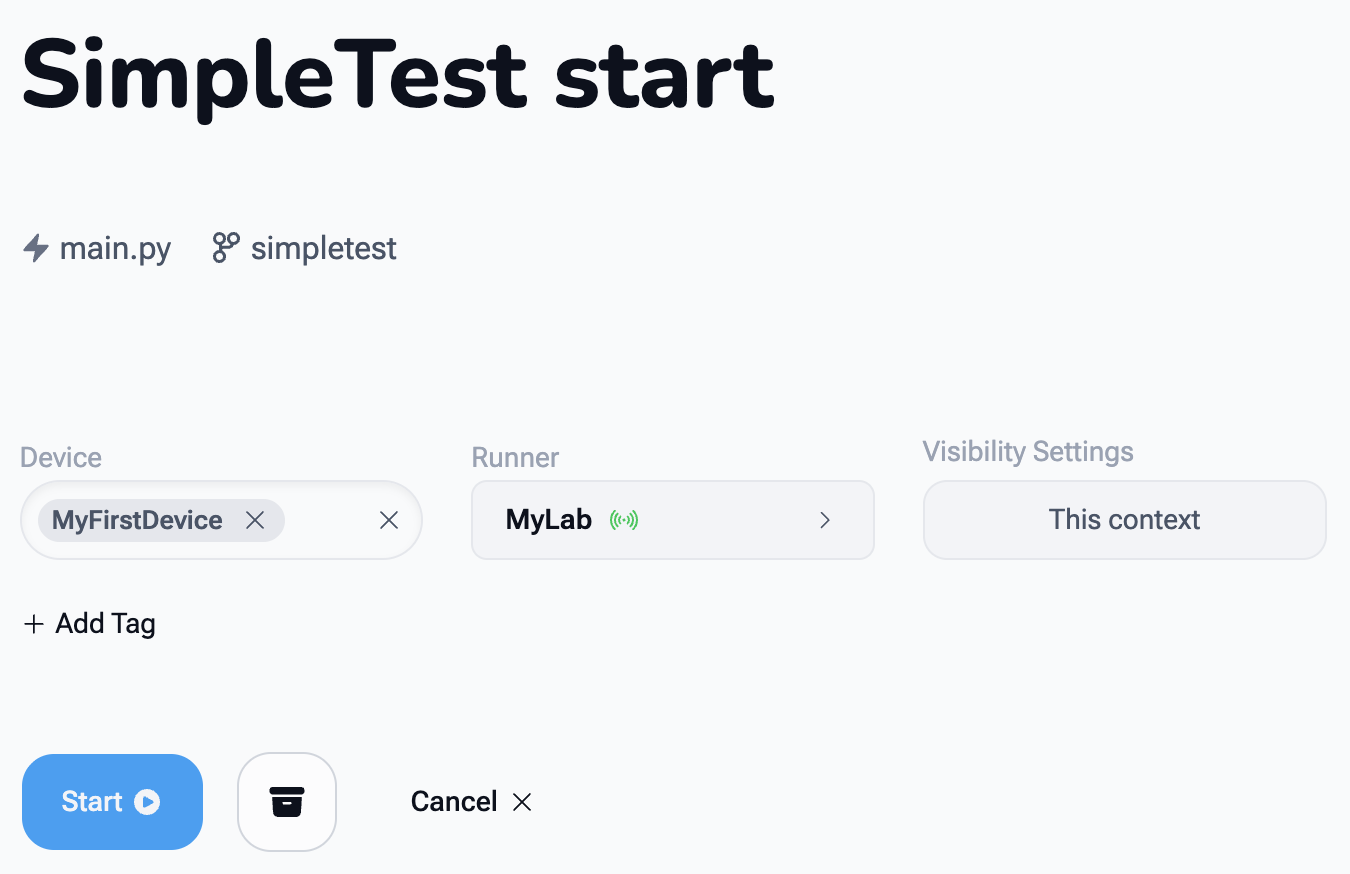
6. Start the Flow¶
- Click the Start button to run the Flow
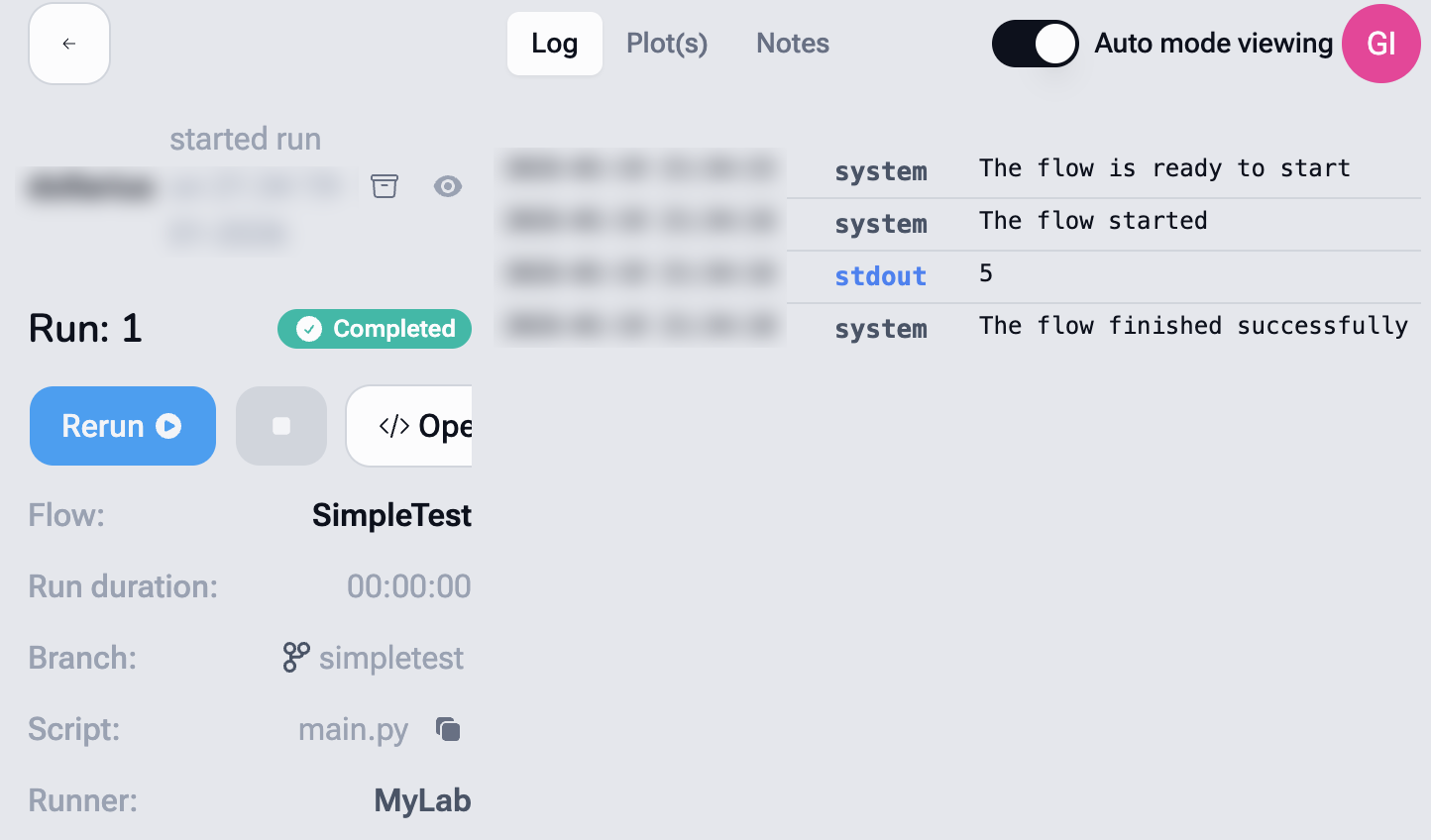
The script executes on the selected Runner, and the standard output (stdout) is automatically captured by Balthazar.
In this example, the output 5 is recorded as part of the Flow execution.
Imports and outputs¶
Balthazar integrates seamlessly with standard Python libraries installed on the machine running the Balthazar Runner.
Plots generated inside a Flow are automatically detected and displayed in Balthazar. This live plotting feature allows you to:
- Inspect results during the run, as plots are captured in real time
- Review results after the run, with plots stored alongside the run metadata
Example: Generating a live plot¶
import numpy as np
import matplotlib.pyplot as plt
# Generate data
x = np.linspace(0, 360, 50)
y = np.sin(np.deg2rad(x))
# Create figure
plt.figure()
plt.xlabel("Angle (deg)")
plt.ylabel("Sine")
# Plot points one by one with a pause to simulate live data taking
for xi, yi in zip(x, y):
plt.scatter(xi, yi)
plt.pause(0.2)
The code above produces the following live plot in Balthazar:
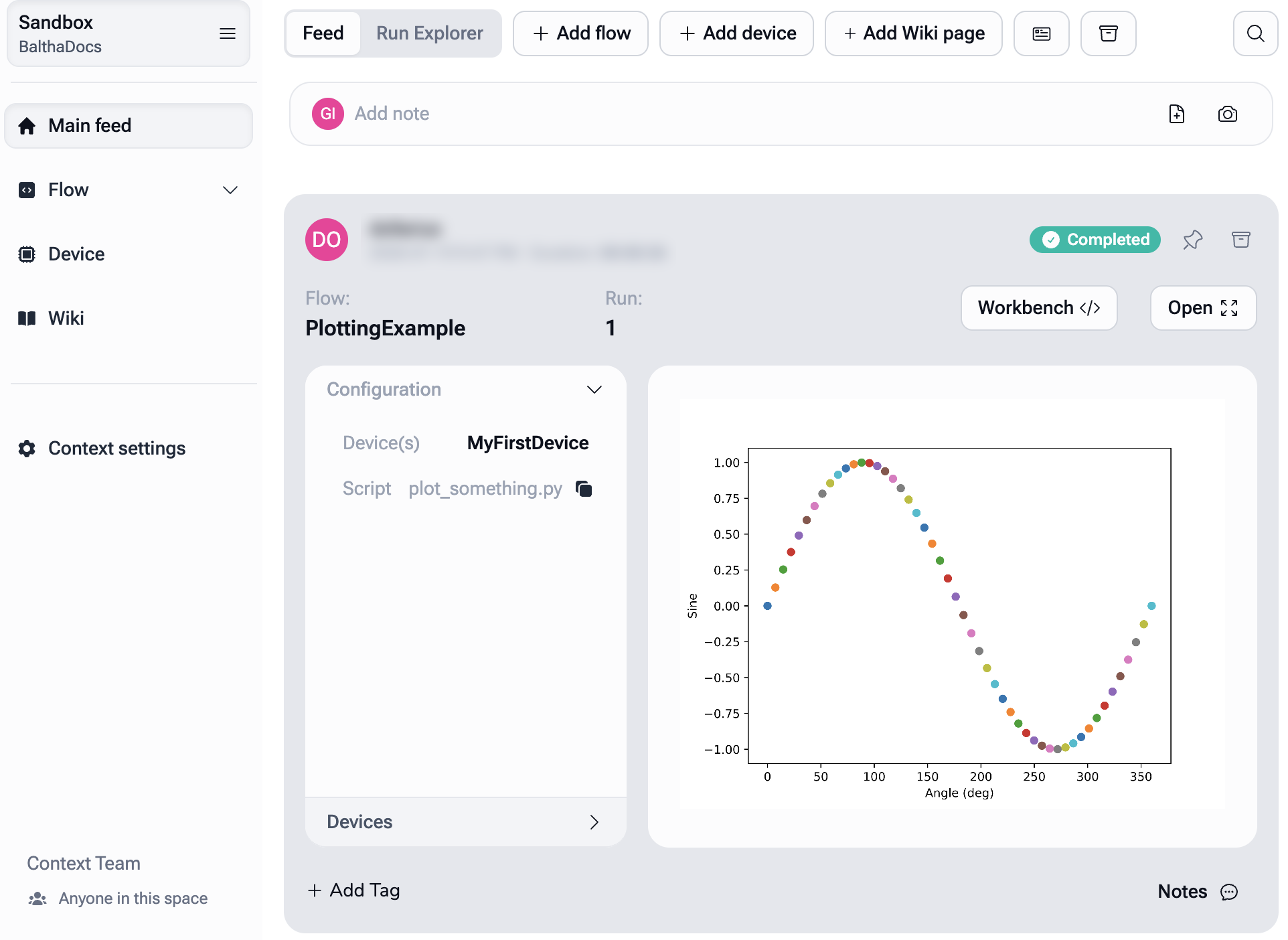
Connecting to instruments¶
Balthazar integrates with instruments using Python libraries such as pyvisa.
Libraries specific to a given instrument can also be imported.
Below is an example of connecting to a Keithley digital multimeter using PyVISA and reading a DC voltage.
import pyvisa
# Create a VISA resource manager
rm = pyvisa.ResourceManager()
# Open a connection to the Keithley instrument over USB
keithley = rm.open_resource("USB0::0x05E6::0x6500::01234567::INSTR")
# Identify the instrument
print(keithley.query("*IDN?"))
# Configure the instrument to measure DC voltage
keithley.write(":SENS:VOLT:DC")
# Read the voltage
voltage = keithley.query(":READ?")
print(f"Measured voltage: {voltage.strip()} V")
Adding outputs¶
To add outputs to the current Flow run:
import balthazar as blt
blt.output[key] = value
If you have a pandas DataFrame df_output containing outputs, you can convert it to a dictionary of lists using df_output.to_dict(orient="list") and then:
for key, value in df_output.items():
blt.output[key] = value
Version control with GitHub¶
Flows are stored in GitHub repositories, making it easy to track both their contents and how they evolve over time.
By using GitHub, you get:
- Automatic branching: a dedicated GitHub branch is created for each Flow.
- Built-in versioning: every time a Flow runs, the files it contains are pushed to the repository, capturing the exact state of the code.
- Full traceability: for every experiment, you can inspect precisely which code was executed.